Multi-Agent Harness — AI Agents That QA Each Other's Code
Built a full multi-agent development pipeline over one weekend. 19 automated sprints, 94% QA pass rate, $0.03/sprint average cost. The system built its own dashboard.
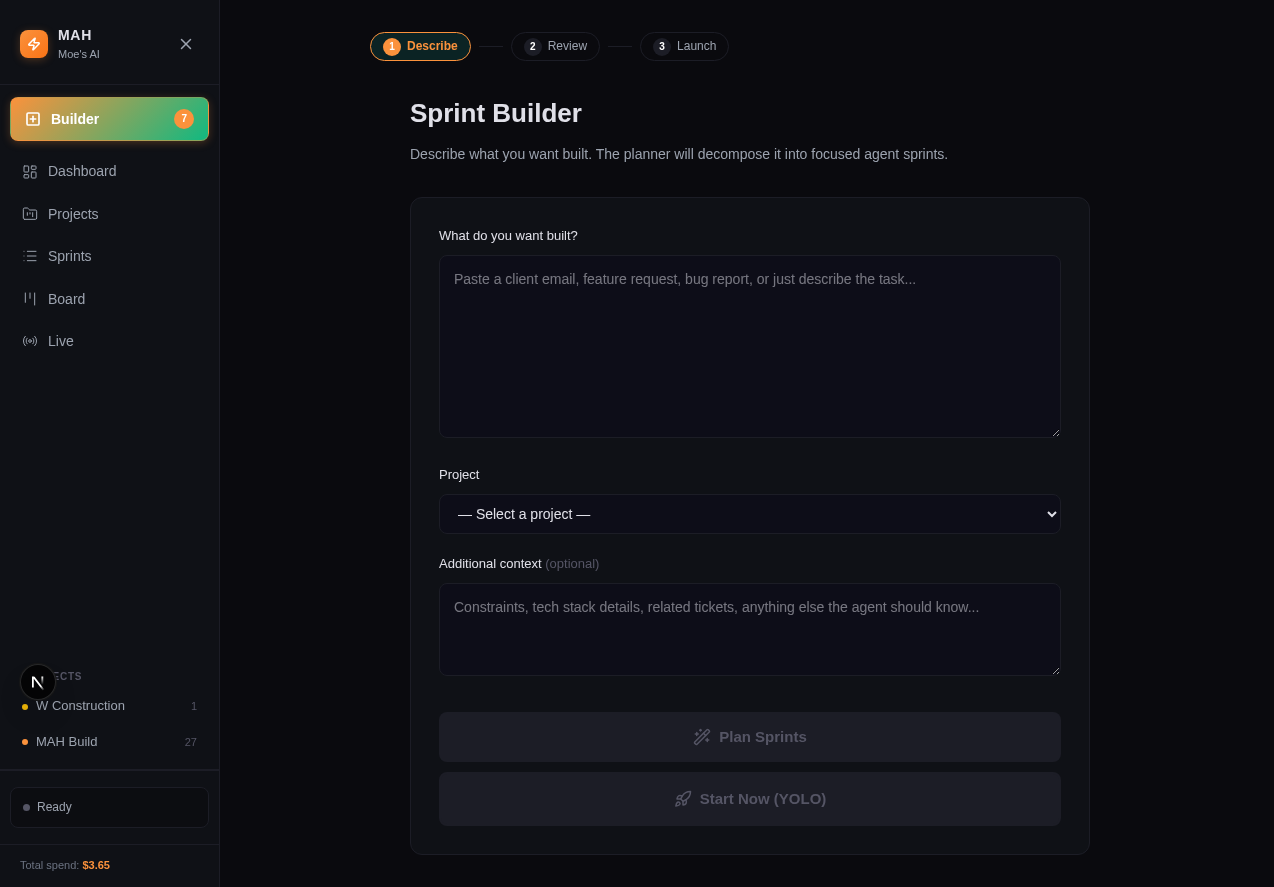
Key Results
The Challenge
Building software with AI agents works well for isolated tasks. Real projects are harder.
A frontend change depends on a backend API. QA catches what the developer missed. Crashed processes lose progress. And when the same agent writes the code and evaluates it, you get the AI equivalent of grading your own homework — fast, but unreliable.
Single-agent workflows can't handle this. You end up babysitting each step, copy-pasting output between tools, and manually restarting when something breaks. The human becomes the glue.
The Approach
We built the Multi-Agent Harness (MAH): a TypeScript CLI and Next.js dashboard that orchestrates specialized agents through a structured development cycle.
The pipeline has four stages:
Planning. An Opus-class model decomposes requests into focused sprints and assigns each one to the right agent. UI changes go to the frontend specialist. API work goes to the backend dev. Research goes to the research agent.
Contract Negotiation. Before any code is written, the dev agent proposes a definition of done. The QA agent reviews and tightens the pass criteria. Both agents agree on the contract. The human just reviews the final version.
Execution. The dev agent writes code. The QA agent evaluates it against the contract. If it fails, findings route back to the dev agent automatically — up to 3 rounds before the sprint is marked failed.
Recovery. Crashed sprints resume from transcript. The executor reads the previous run and picks up from the last completed phase. On one re-run, this saved ~50% of the execution cost by skipping phases that had already passed.
The Dashboard
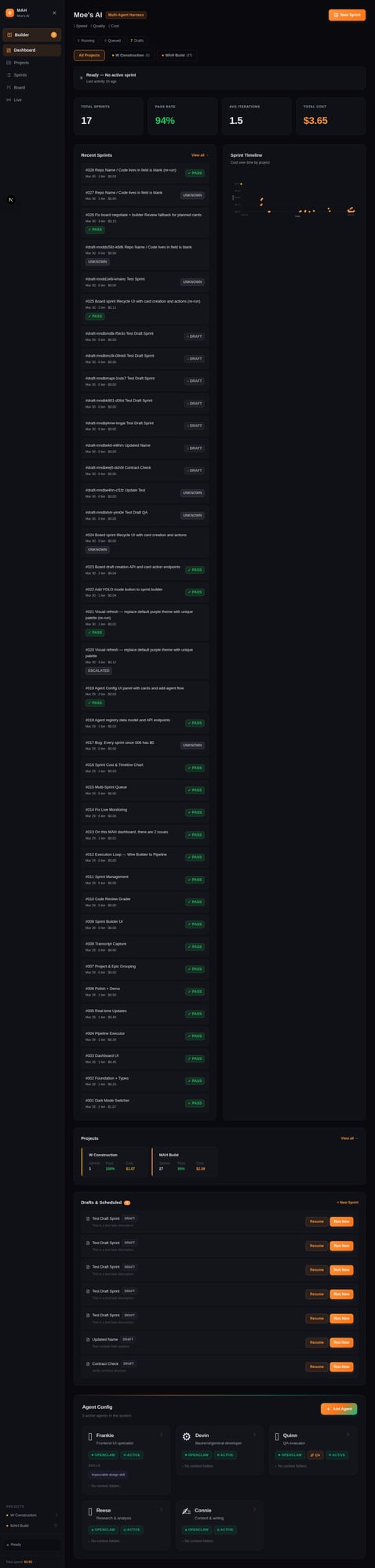
The Next.js dashboard provides real-time visibility: live sprint execution via heartbeat polling, cost timeline, sprint history, a kanban board, sprint builder, and agent configuration. Everything writes JSON — sprint transcripts, QA findings, cost per phase — for future replay and audit.
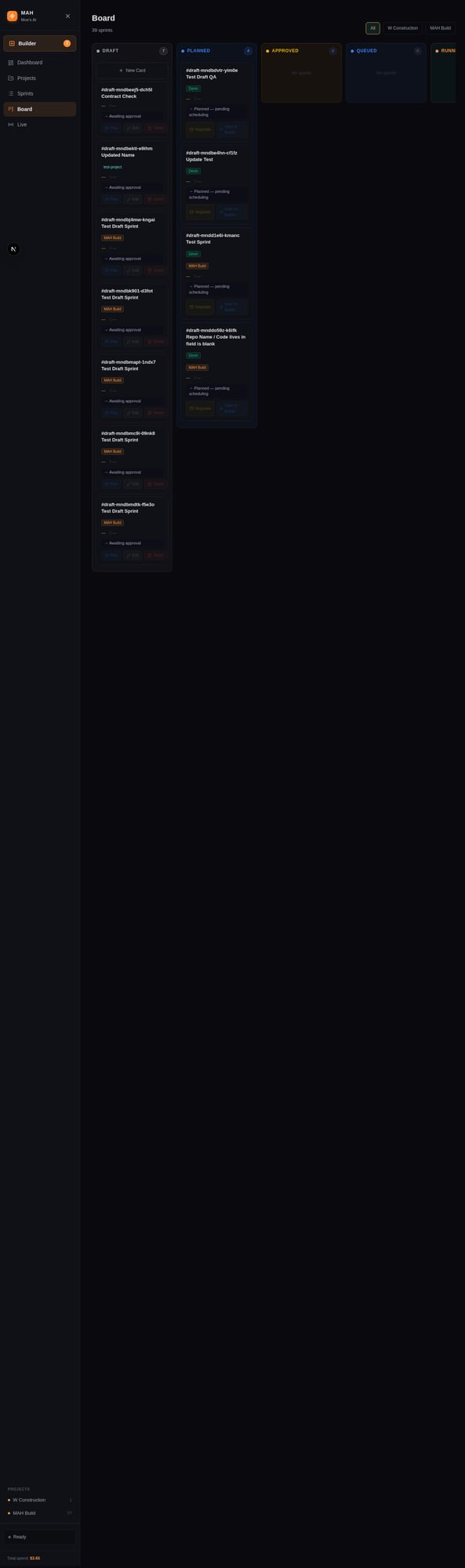
Sprints move through five states: Draft → Planned → Approved → Queued → Running → Done (or Failed). The human gate is between Planned and Approved — review the contract, approve the sprint, the pipeline handles the rest.
The Results
19 sprints over one weekend. 18 passed QA on the first or second attempt. One failed — a cost tracking bug where the sprint passed QA on surface behavior but had a deeper data issue. The system caught it, marked it failed, and moved on.

The most satisfying part: Sprint 016 added a cost timeline chart to the dashboard. It was planned, built, QA'd, and deployed by the same pipeline — running on the dashboard it was extending. The system built part of itself.
Sprints 017–019 continued: cost display fixes, agent registry, agent config UI. All delivered by the harness.
The Key Insight
The value isn't in the models. It's in the orchestration layer.
Separation of concerns matters. When the same agent writes and evaluates code, quality is inconsistent. When a dedicated QA agent grades against a negotiated contract, it's structured — predictable, auditable, improvable.
The same principle applies to recovery. Agents crash. Processes die. Networks timeout. A harness that reads its own transcripts and resumes from the last checkpoint turns brittle automation into resilient infrastructure.
Service Availability
MAH is available as a service through GTA Labs:
MAH Starter ($1,500) — Pre-configured 5-agent setup cloned for your projects. Dashboard, pipeline, five specialized agents, pre-configured quality tiers. Running sprints within a week.
MAH Custom ($4,000) — Custom agent roster designed for your workflow. Codebase analysis, custom evaluation criteria, specialized skills for your domain. Full harness setup. You own everything.
Compatible with Claude Code, OpenClaw, NemoClaw, Codex, or custom agent platforms. No recurring fees, no vendor lock-in.