I Built a System Where AI Agents QA Each Other's Code for 3 Cents
How a weekend project turned into a multi-agent development harness — where a planner, dev agent, and QA agent negotiate contracts and run 19 sprints for under $1.

Last weekend I wanted to build a dashboard. Instead of building it myself, I built a system that builds things for me, then used it to build the dashboard. Then the dashboard built more of itself.
That's not a riddle. It's what happens when you stop thinking about AI agents as individual tools and start thinking about them as a team.
The Problem With Single-Agent Coding
We've all used AI coding assistants. They're good at writing code. They're bad at knowing when the code is wrong.
The issue isn't capability — it's structure. When the same agent writes the code and evaluates it, you get the AI equivalent of grading your own homework. It's fast, but it's unreliable.
The fix isn't better models. It's separation of concerns.
The Harness Pattern
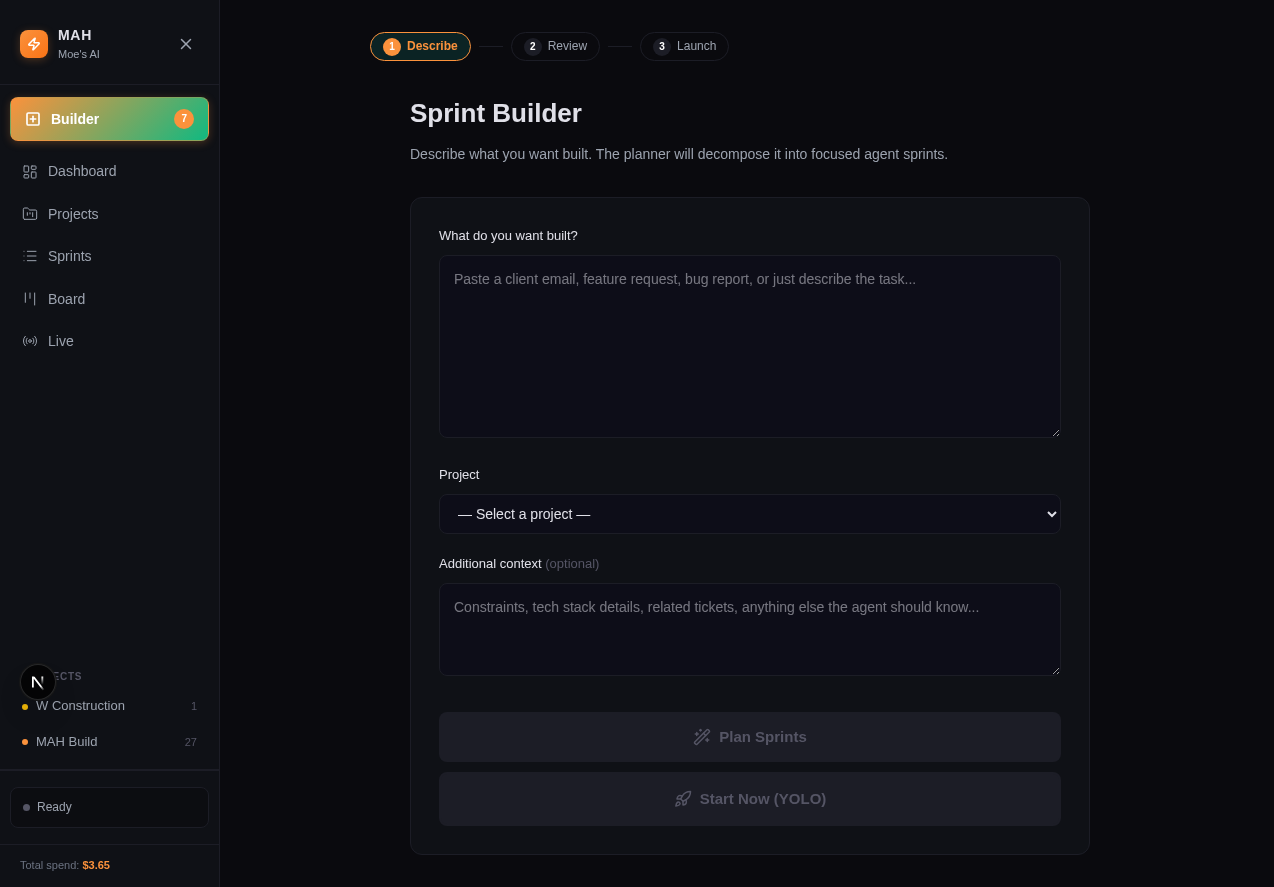
The sprint builder: describe what you want, the planner handles the rest.
The Multi-Agent Harness (MAH) runs development work through a pipeline that mirrors how human teams actually operate:
1. Planning You describe what you want in plain English. An Opus-class model decomposes the request into focused sprints and assigns the right agent to each one. A UI change goes to the frontend specialist. An API endpoint goes to the backend dev. Research goes to the research agent.
2. Contract Negotiation Before any code is written, the assigned dev agent proposes a definition of done. Then the QA agent reviews it and tightens the pass criteria. This negotiation happens automatically — the human just reviews the final contract.
3. Execution The dev agent writes code. The QA agent evaluates it against the contract. If it fails, the dev agent gets the QA findings and tries again. Up to 3 rounds.
4. Recovery If a sprint crashes mid-execution (network timeout, process killed, pipe broken), the harness reads the transcript from the previous run and resumes from the last completed phase. No wasted work.
The Numbers
Over a weekend, I ran 19 sprints through this system:
| Metric | Value |
|---|---|
| Sprints run | 19 |
| Pass rate | 94% (18/19) |
| Average cost | ~$0.03/sprint |
| Total spend | < $1.00 |
| Self-built sprints | 4 (the dashboard built parts of itself) |
The one failure was a metrics display bug where the sprint passed QA but the cost tracking had a deeper issue. The system caught it, marked it as failed, and moved on.
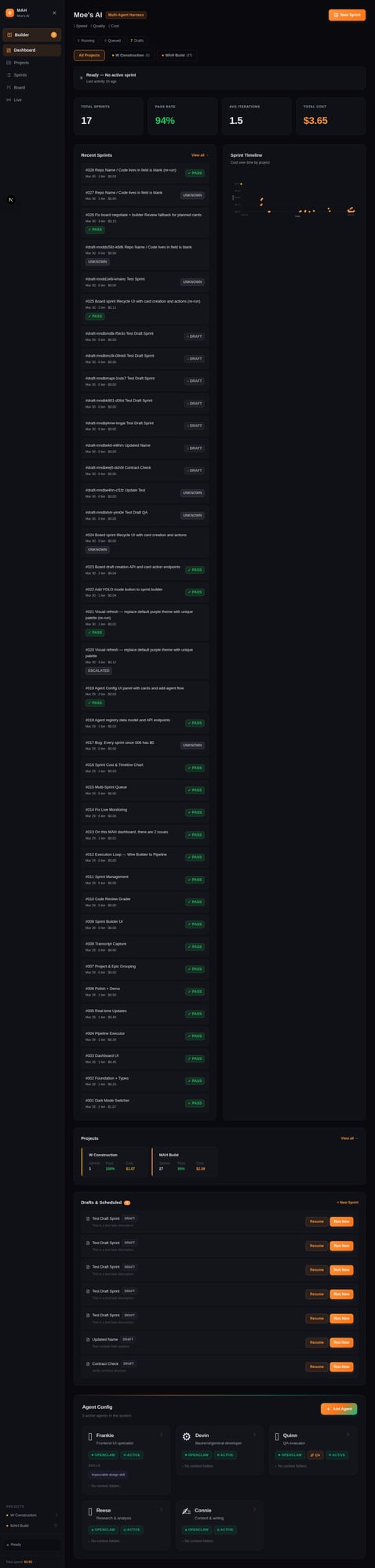
The dashboard tracking 19 sprints — cost timeline, pass rates, and live status.
Agents, Not Models
The key insight is that agents aren't models. A model is a capability. An agent is a capability plus context, personality, standards, and specialization.
Each agent in the harness has:
- A soul file — who they are, how they work, what they care about
- Skills — specialized knowledge loaded based on the task
- Quality tiers — not every task needs the same level of polish
The frontend agent gets a design brief with theme tokens and anti-patterns ("no gradient backgrounds, no glowing borders, no centered-everything layouts"). The QA agent grades on five dimensions: navigation, layout, interactivity, performance, and visual consistency.
This isn't about making AI "creative." It's about making AI predictable and specialized.

A sprint in action: dev agent output, QA findings, and the fix cycle.
The Self-Building Part
The most satisfying moment was when Sprint 016 — "add a cost timeline chart to the dashboard" — was built by the pipeline, for the dashboard, running on the dashboard.
The system built the feature that tracks how much the system costs to run.
Sprints 017-019 continued the pattern: fixing cost display bugs, building an agent registry, and creating the agent config UI. Each one planned, executed, QA'd, and delivered by the same harness.
What's Under the Hood
MAH is a TypeScript CLI paired with a Next.js dashboard. The pipeline shells out to claude --print for each agent turn, captures the output, and feeds it to the next stage. It's not a framework — it's a harness. You plug in your own agents.
Compatible with:
- Claude Code — what we use for dev agents
- OpenClaw — agent orchestration layer with skills, memory, and multi-channel support
- NemoClaw — NVIDIA's enterprise policy engine for sandboxed execution
- Codex — OpenAI's agent platform
- Custom agents — anything that takes a prompt and returns output
The dashboard shows live execution (heartbeat polling), sprint history, a kanban board, cost tracking, and a builder for creating new sprints. Everything writes JSON for future video rendering of sprint replays.
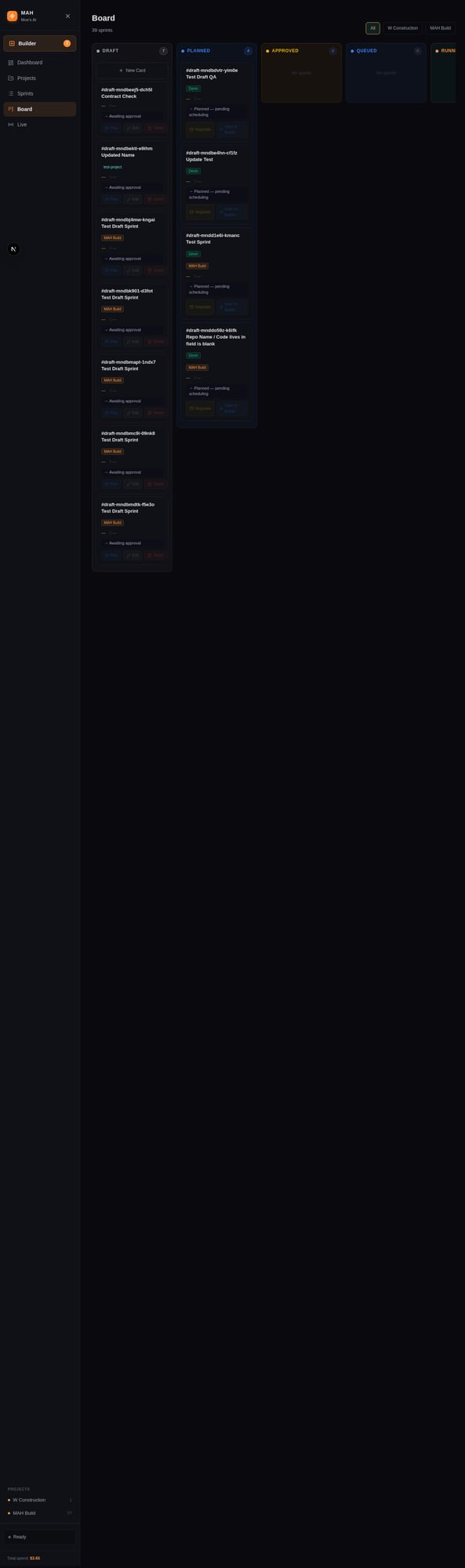
The kanban view: sprints move from draft through approval to execution automatically.
Try It
We're offering MAH setup as a service through GTA Labs:
MAH Starter — $1,500 Our proven 5-agent setup cloned for your projects. Dashboard, pipeline, five specialized agents (frontend dev, backend dev, QA, research, content), pre-configured quality tiers. You're running your first sprint within a week.
MAH Custom — $4,000 Custom agent roster designed for your workflow. We analyze your codebase, define your evaluation criteria, build specialized skills for your domain, and set up the full harness. You own everything — no recurring fees, no vendor lock-in.
Both include a week of setup, a walkthrough of the system, and documentation for your team.
Greg Mousseau is the founder of GTA Labs, an AI consulting firm in Toronto. He builds agent infrastructure for teams that want AI to do more than autocomplete.