The 4 Layers of AI Agent Platforms (And Why Layer 4 Doesn't Exist Yet)
The AI agent ecosystem has quietly split into four distinct layers. Most teams are picking tools without understanding which layer they're actually buying into.
I've spent the last year helping companies evaluate AI agent tooling. The same confusion keeps showing up: teams compare tools that aren't even in the same category. Someone will ask me whether they should use CrewAI or Lindy AI, and it's like asking whether you should use React or Figma. They solve different problems at different altitudes.
The AI agent space has quietly split into four layers. Understanding which layer you're operating at changes everything about how you evaluate tools, what you spend, and what you should expect.

Layer 1: Frameworks
This is where it all started. CrewAI, LangGraph, AutoGen, the OpenAI Agents SDK, OpenAgents. These are developer tools. You install a Python package, write code, define agents, wire up tool calls, and run everything from a script or server.
The control you get is real. You can define exactly how agents collaborate, what tools they access, how they handle errors. LangGraph gives you state machines for complex workflows. CrewAI lets you define agent roles and have them delegate work to each other. The OpenAI Agents SDK dropped in early 2025 and made it dead simple to spin up tool-calling agents with built-in handoff patterns.
Here's what bugs me about this layer: the gap between "I built an agent" and "other people can use my agent" is enormous. Your agent lives in a Jupyter notebook or a Python script. There's no dashboard. There's no way for a product manager to trigger it. There's no monitoring. If it fails at 2am, nobody knows until someone checks the logs.
Frameworks are great for prototyping and for teams with strong engineering culture. But I keep seeing companies build impressive demos in LangGraph, then spend three months building the infrastructure around it just so non-developers can interact with the thing. That infrastructure work is unglamorous and expensive, and it's where most agent projects quietly die.
Layer 2: No-code builders
Lindy AI, Relevance AI, Gumloop, Beam. These platforms took the Zapier playbook and added AI. You get a visual canvas, drag-and-drop nodes, pre-built integrations. A marketing ops person can build an agent that monitors a Gmail inbox, classifies incoming leads, and pushes them to a CRM. No code required.
The pitch is compelling. And for simple workflows, these tools genuinely deliver. I've seen teams get real value from Lindy for things like email triage and meeting prep.
But there's a ceiling, and you hit it fast.
Most of these platforms charge $50 to $300 per month, and that's before you factor in per-execution costs. Relevance AI's pricing scales with "credits" that burn faster than you'd expect once agents start making multiple LLM calls per task. Lindy's Pro plan is $99/month for 5,000 credits. That sounds like a lot until you realize a single multi-step agent run can eat 20-30 credits.
The deeper problem is autonomy. These agents don't remember anything between runs. They can't learn from past executions. They can't adapt their behavior based on what worked last time. Every run is a blank slate. You're essentially building elaborate prompt chains with a nice UI on top.
Try to build something genuinely complex, like an agent that researches a topic across multiple sources, synthesizes findings, then drafts a report with citations, and these platforms start breaking down. The visual canvas becomes a spaghetti diagram. Error handling is limited to "retry" or "stop." And when something goes wrong in the middle of a 15-step workflow, good luck debugging it.
Layer 3: Ops and observability
This layer emerged because the first two layers created a monitoring vacuum. You build agents in Layer 1 or Layer 2, and then you need to answer questions like: How much are my agents costing me? Which ones are failing? What did the agent actually do during that 45-second run?
AgentOps and LangSmith are the big names here. AgentOps gives you session replay for agent runs, so you can watch exactly what happened step by step. LangSmith (from the LangChain team) provides tracing, evaluation, and dataset management. Both are genuinely useful. If you're running agents in production, you need something like this.
OpenClaw has its own take on this with Mission Control, which adds approval workflows on top of monitoring. The idea is that some agent actions should require human sign-off before executing.
I see this layer as necessary but insufficient. These tools watch your agents. They don't make your agents better. They're dashboards, not brains. You still need a developer to interpret the data, identify problems, and manually update agent configurations. The feedback loop is human-mediated and slow.
There's also a practical gap: these tools assume you already have agents running somewhere. They don't help you build or deploy agents. They're the observability layer for an ecosystem that's still figuring out the layers below it.
Layer 4: Self-managing agents
This is where things get interesting, because this layer is just starting to emerge.
Since I drafted this post, OpenAI shipped Codex security. I'll cover it properly in an upcoming piece, but it's worth noting here: Layer 4 might not be as far off as I thought.
I keep thinking about what a truly self-managing agent would look like. Not an agent that executes a predefined workflow. Not an agent that needs a developer to update its prompts when requirements change. An agent that genuinely manages itself.
It would need persistent memory that spans sessions and accumulates over time. When you correct it on Tuesday, it remembers on Friday. When a particular approach fails three times, it stops trying that approach. Today's agents are goldfish. Every conversation starts from zero.
It would need to live across multiple channels. Not just "I can send a Slack message," but actually existing in Slack, email, your calendar, your codebase. Present where you are, not locked behind a separate UI that you have to remember to open.
It would need self-improvement that actually works. Not just "I logged that error." Real behavioral change. The agent notices it keeps getting corrected on a specific type of task, so it adjusts its approach. It develops preferences based on what its user actually wants, not what the default prompt says.
And the thing that makes this genuinely hard: it would need to do all of this without becoming a black box. If your agent quietly changed its own behavior and you couldn't understand why, that's terrifying. Self-management requires transparency. The agent should be able to explain what it learned, when it learned it, and why it changed.
Almost nobody has built this. OpenClaw is the exception worth paying attention to.
It's the first of its kind in this category — open source, with persistent memory across sessions, multi-channel presence (Telegram, Slack, WhatsApp, Discord), and actual self-improvement loops baked in rather than bolted on. The GitHub star growth has been something to watch.
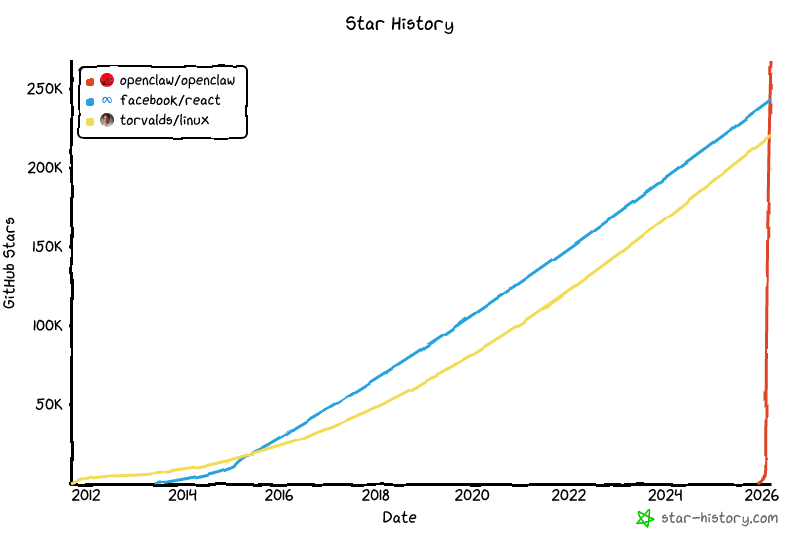
That kind of momentum tends to invite a response. Notion shipped an agent mode. Anthropic launched Claude Remote. OpenAI folded agents more deeply into the GPT product. Perplexity added agentic layers to search. There's a new "AI agents" announcement most weeks now.
Most of them feel like toys. Sometimes useful toys. But they're largely Layers 1 and 2 with more polished marketing, not genuinely self-managing systems.
OpenClaw is different. But I want to be honest about what that means right now: it's nowhere near enterprise ready, and calling it production ready would be generous. I use it. I build on it. The capabilities are real in a way that nothing else in this space is. But I cannot set it up for a non-technical user without some pretty serious handholding. The configuration is dense, the failure modes take experience to navigate, and a working knowledge of how agents actually function is assumed everywhere. It's a power tool without guard rails, which is exciting if you know what you're doing and alarming if you don't.
If you can harness it, you get access to things that don't exist anywhere else at this layer. I'm writing a full post on what harness engineering actually means in practice — watch for that one.
What I'll say about the pace of change: OpenClaw development is moving fast enough that it wouldn't shock me if a version meaningfully accessible to non-technical users shows up in the next month or two. That's not a prediction. It's just an observation about velocity.
The reason Layer 4 is hard isn't only engineering. Layers 1 through 3 are hard engineering problems, but solvable with known techniques. Layer 4 is a design problem. How do you build trust with a system that changes its own behavior? How do you give an agent enough autonomy to be useful without giving it so much that it becomes unpredictable? Where do you draw the line between "the agent figured it out" and "the agent went off the rails"?
OpenClaw is wrestling with those questions in public. That alone makes it worth tracking.
What this means for your stack
If you're evaluating agent tooling right now, the most important question isn't "which tool is best." It's "which layer am I buying into?"
If you have a strong engineering team and specific, well-defined agent use cases, Layer 1 frameworks give you the most control. Expect to invest in the infrastructure around them — or bring in a fractional AI lead to accelerate it.
If you need quick wins for business process automation and your workflows are relatively straightforward, Layer 2 builders can get you there. Just be realistic about the ceiling.
If you're already running agents in production, Layer 3 observability isn't optional. You need visibility into what your agents are doing and what they're costing you — a reliability upgrade can help you get there.
And Layer 4? I genuinely think whoever figures it out will change the industry. Not because self-managing agents are a nice feature, but because every other layer still requires a human to be the brain. The agent does the work, but a person decides what work to do, how to do it, and what to change when things go wrong. That's a bottleneck. It's the bottleneck.
The interesting question isn't whether Layer 4 will arrive. It's whether it'll emerge from one of the existing layers evolving upward, or from something completely new that we haven't seen yet.